As the complexity of a system grows, so does the need to separate it into independent software modules. This way, non-trivial software systems are more easily understood, tested and evolved. In programming languages, there are many different ways to achieve modularity. In object-oriented programming, a complex object usually contains multiple simpler objects, where each part implements a certain functionality. In functional programming, a function calls simpler functions to compute a value, or is composed from simpler functions using functional combinators. Distributed systems are often separated into independent, concurrent processes, each of which assumes a particular role. We refer to this as composition, and say that programming abstractions compose if it is possible to create more complex abstractions from simpler ones.
Scala coroutines compose in a similar way functions (i.e. subroutines) do. Code inside a coroutine can directly invoke another coroutine, as if it were a normal function call. This allows separating functionality across multiple simpler coroutines, and composing them together. In this section, we will see the details of how this works.
Calling a coroutine directly
In Coroutines 101,
we learned that normal program code cannot invoke a coroutine directly,
and must use the call statement instead,
to obtain a coroutine instance object.
Assume that we have a simple coroutine that yields
the integers in an Option[Int] object.
This coroutine will either yield a single integer, or none.
val optionElems = coroutine { (opt: Option[Int]) =>
opt match {
case Some(x) => yieldval(x)
case None => // do nothing
}
}
Now, assume that we need to yield integers from a list of optional integers,
that is, a List[Option[Int]] value.
We need a coroutine optionListElems, that will yield these integers.
We could write an entirely new coroutine that traverses the Option[Int]
elements in the list in a while loop,
and then do the pattern match again on each element.
Sound software engineering principles such as DRY
tell us to reuse the existing optionElems coroutine instead
of duplicating the pattern match.
We implement a new coroutine optionListElems as follows.
Each time a while loop iteration stumbles upon a new optional value,
it invokes the existing optionElems method with that optional value.
This is shown in the following snippet:
private val optionListElems = coroutine { (xs: List[Option[Int]]) =>
var curr = xs
while (curr != Nil) {
optionElems(curr.head)
curr = curr.tail
}
}
What happened here?
We are using the coroutine optionElems as if it were a regular function!
Instead of putting it into a call statement,
we’re just invoking it directly!
Why is this allowed inside a coroutine,
but it was not allowed in the regular program code?
The reason is that the coroutine instance is executing in a special environment
where yielding is possible.
This environment includes a special stack, as we saw in Coroutine 101,
which is used to store the local variables of the coroutine instance
when a yieldval occurs.
A coroutine instance can use this stack to seamlessly store
the variables belonging to another coroutine and continue execution.
If the code in the other coroutine also executes a yieldval statement,
the coroutine instance stack will contain the local variables of both coroutines.
 |
Code within the coroutine can call another coroutine directly,
as if it were a normal function.
The code within the second coroutine continues to execute within
the same coroutine instance,
and yields values back to the caller of resume.
|
Let’s verify that this works – we instantiate a list of optional integers,
and start the optionListElems coroutine.
We then verify that only non-None values are yielded:
val xs = Some(1) :: None :: Some(3) :: Nil
val c = call(optionListElems(xs))
assert(c.resume)
assert(c.value == 1)
assert(c.resume)
assert(c.value == 3)
assert(!c.resume)
After the coroutine instance c yields values 1 and 3,
calling resume returns false, indicating that the coroutine terminated.
This is consistent with what we expect – the only yieldval statement
exists in the optionElems coroutine, and it is called for the two Some objects.
Taking a step back, we can see that this feature allows factoring out functionality across multiple coroutines. In the coroutine call stack, low-level coroutines yield values by traversing simpler data structures, and higher-level coroutines invoke them as needed. Composition is achieved through coroutine invocations.
|
Note that if a directly invoked coroutine throws an exception, then the exception is propagated up to call stack until reaching the boundary of the coroutine instance. |
You can see the complete example below.
Starting a coroutine instance vs. calling a coroutine
Instead of invoking another coroutine directly,
we might be tempted to start a new coroutine instance inside the coroutine,
and then traverse its values with resume and value, as follows:
private val optionListElems = coroutine { (xs: List[Option[Int]]) =>
var curr = xs
while (curr != Nil) {
val c = call(optionElems(curr.head))
while (c.resume) yieldval(c.value)
curr = curr.tail
}
}
There are also several downsides to this approach.
First of all, this is slower than invoking the coroutine directly.
Second, it is syntactically less concise.
Finally, the implementation above does not propagate exceptions
that are potentially raised in the nested coroutine instance c.
This is not to say that starting a new coroutine instance (call)
does not have its own use-cases.
Starting a new coroutine instance is a different form of composition
which achieves a higher level of separation between the two coroutines.
For example, the newly started coroutine instance
could be yielded back to the caller,
who then decides what to do with it.
The coroutine that started a new coroutine instance
is under no obligation to complete it.
On the other hand,
a coroutine that invoked another coroutine directly
can only continue executing after the nested coroutine completes –
this is semantically exactly the same as a function call.
If we take a look under the hood,
we see that the difference between starting a coroutine instance (call)
and invoking the coroutine directly
is in the location where the nested code is execution.
Shown graphically,
starting a new coroutine instance looks as follows:
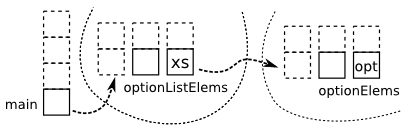
We can see that using call creates two coroutine instances in our program,
each executing a different coroutine.
By contrast, invoking a coroutine directly, on the existing coroutine instance, reuses the same stack. This is shown in the following figure.
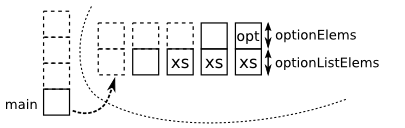
Again, the complete example is shown below.
Summary
The most important concepts to remember from this section are the following:
- A coroutine can invoke another coroutine directly – this behaves in the same way that a function call would.
- When invoked directly, the two coroutines share the same coroutine instance,
and the nested coroutine yields values back to the same caller of
resume. - A direct invocation is different than starting a new coroutine instance with
call– the latter is a more relaxed form of composition. - In most situations, we want to use direct coroutine invocation inside a coroutine.
In the next section, we take a look at an alternative way of transferring control flow to another coroutine.